发布日期:2026-03-23 08:06 点击次数:99


机器之心剪辑部
这两年,扩散言语模子(Diffusion LLM)一直是个很有究诘度的标的。
和传统自纪念模子不同,扩散模子不是严格按从左到右一个 token 一个 token 往外吐,它在生成样式上更纯真,也自然更合适并行建模。可问题也一直摆在那儿:这条路很有后劲,但的确把牺牲作念上去并辞谢易。
最近有一篇来自华为诺亚方舟践诺室的职责,研究了扩散模子进修中的 “默许诞生”。论文标题叫 Mask Is What DLLM Needs: A Masked Data Training Paradigm for Diffusion LLMs。作家莫得先去改模子结构,而是把目力放回了进修过程里一个看起来很基础、但其实一直被默许经受的设定:masking 到底该何如作念。

论文王人集:https://arxiv.org/abs/2603.15803
数据集王人集:https://huggingface.co/datasets/malr07/opc-sft-stage2-dense-extracted
这篇著作给出的判断是,现存许多闹翻扩散言语模子在进修时经受的均匀马上 masking,其实有点 “平均使劲” 了。
这个问题在一般文本里可能还没那么明显,但到了代码和数学推理任务上,就会变得很特出。因为这类数据里,的确决定模子能不可作念对的,通常仅仅少数几个重要位置:在代码任务里,可能是重要的分支要求、判断逻辑;在数学里,可能是重要的化简智商、函数替换,这些东西明显比勾引词大致表情内容更进军。事实上,的确序列里的信息密度原来就不是均匀散播的,而传统马上 masking 却默许每个位置都差未几,这会被迫地让模子把不少优化资源花在不那么重要的所在。
说白了,即是模子学的技术没太分清主次,通盘东西都一样对待了。
不是通盘 token 都一样进军
这篇职责的中枢想法其实一句话就能详尽:
既然不同 token 的信息量不一样,那进修时就不该对它们一视同仁。
围绕这个想法,作家提议了一个愈加 Smart(Input Information Density Aware)的 Noise Scheduler。它作念了一件很精真金不怕火且直不雅的事情:先想办法把样本里那些 “信息密度高” 的位置找出来,然后在进修时更优先地 mask 掉这些位置,逼着模子去学会还原的确重要的部分。
这套作念法背后的直观其实很自然,东说念主作念完形填空的技术,也不会认为补一个逗号和补一句重要论断的难度是一样的。的确能拉开差距的,连续即是那些牵一发而动全身的所在。论文里也提到,这种瞎想的直观和东说念主类的挖空老练很接近:更高效的学习,通常不是去还原冗余内容,而是去还原中枢观念。
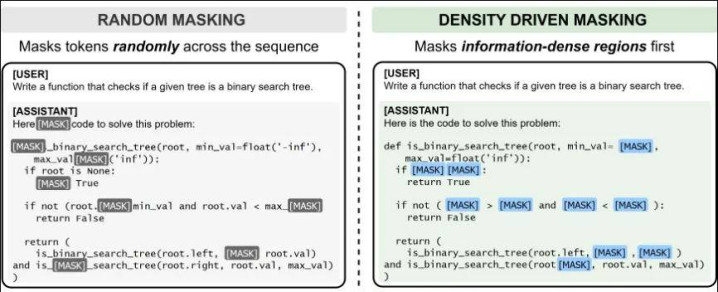
先找 “要点”,再决定何如 mask
具体作念法上,作家先作念了一步高信息密度区域索要(Step 1)。
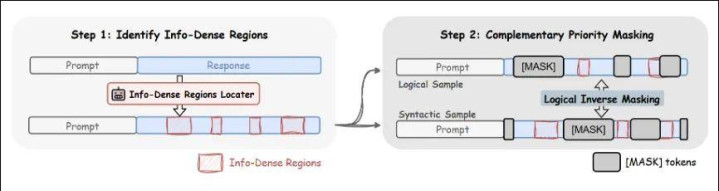
对于代码数据和数学数据,作家瞎想了一些不同的 criteria。将数据中的重要信息区域索要出来之后,这些区域会在原始序列中被高亮秀雅出来,背面进修时的噪声交流就会参考这些特殊秀雅。
接下来参加的确的 masking 阶段(Step 2)。和传统作念法不同,这里不是通盘位置都按雷同概率被 mask。作家把序列分红两类:一类是优先区域,也即是那些信息密度高的 token;另一类是粗造区域。前者会被赋予更高的 mask 概率,后者保持较低概率。与此同期,合座的 mask 比例仍然会被界限住,不会因为 “偏心” 了某些位置就把通盘这个词噪声交流搅散。
这个瞎想最重要的少量在于,它不是单纯 “多遮少量”,而是把进修难点往真恰巧得学的所在推。模子被反复要求补全的,不再仅仅马上缺失的内容,而是那些决定代码是否修复、推理是否走通的重要片断。
另一个工致想:一条数据,两种学法
要是仅仅优先 mask 掉高信息区域,很容易让东说念主纪念另一个问题:模子会不会变得更会 “作念题”,但对言语结构自己?
是以这里引入了扩散模子进修中常用的 Complementary Masking。
想路是:对归并条样本,Trainer 不单笔据前文的 token-level 优先秀雅构造一个 priority mask,还会构造它的总共逻辑互补版块。也即是说,一份样本会酿成两种互补的进修视角:一种把要点放在逻辑骨架上,另一种则更多保留这些重要位置,转而让模子行止理结构、语法和陡立文连贯性。
这种将互补掩码与优先级掩码结合的瞎想获得了一种 1+1>2 的牺牲,因为它莫得把问题简化成 “只须盯住要点就行”,而是承认:言语模子最终如故既要会推理,也得会组织言语。前一种视角更像是在逼模子收拢重要逻辑,后一种视角则是在防范它把句子写散、把陡立文干系学丢。论文把这种牺牲称为一种基于信息密度的 decoupling,内容上是在把一条进修样本里的不同学习宗旨终止。
改改噪声交流就能径直提点
践诺部分,开云体育作家使用 LLaDA-2.0-mini 看成基础模子,在代码和数学数据上进行进修,临了在 HumanEval、MBPP、GSM8K、MATH500 四个 benchmark 上作念评测。牺牲露出,比拟圭臬的马上 masking baseline,这套设施的平均收获擢升了苟简 4%。

这个幅度不属于那种一眼看上去尽头炸裂的数字,但放在这里其实挺有劝服力。原因在于,这项职责并莫得去改 backbone,也莫得上尽头重的迥殊模块,它动的是进修范式自己,两个数字之间唯独的相反唯有噪声交流。换句话说,它不是靠 “再堆少量结构” 把牺牲抬上去,而是讲明了只须进修信号分拨得更合理,扩散模子自己还有不少后劲没被用出来。
有个消融牺牲很值得闪耀:不是越狠越好
论文里另一个有启发性的部分,其实是对于 hard masking 和 soft masking 的比较。
直观上你可能会认为,既然高信息区域进军,那就干脆把这些位置狠狠遮掉,让模子故意练这个,不是更好吗?但践诺牺牲并不是这么。作家发现,细则性的 hard masking 反而容易把进修搞坏,牺牲反而不如带概率的 soft masking。
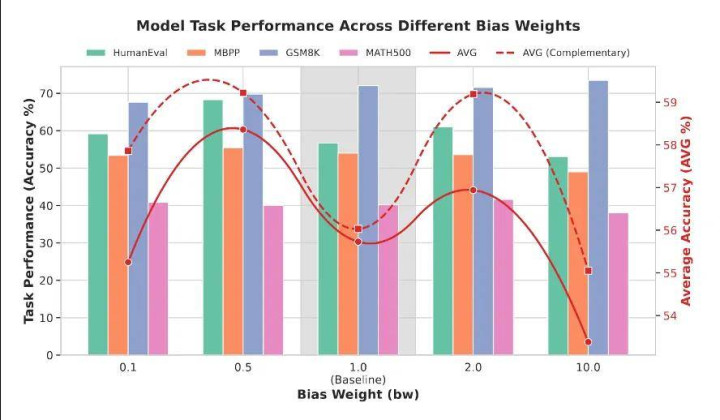
他们给出的解释也挺合理。代码和数学里的高信息区域,许多技术在文本里是连气儿出现的。要是把这一整段连气儿内容都径直硬遮掉,那么在 block diffusion 的进修过程中,就特殊于霎时挖掉了一大片局部锚点,出现了一大片连气儿的 “内容黑洞”。论文把这个征象叫作念 contextual collapse:局部参照一朝没了,进修过程就容易失稳,梯度轨迹也会变得很难界限。比拟之下,soft mask 自然也提高了这些位置被遮掉的概率,但毕竟还保留了马上性,不至于每次都把重要部分通盘这个词掏空,因此优化会平滑得多。
这少量其实挺像许多进修手段临了都会落到的阿谁论断:标的对了不代表力度越大越好,给模子留少量缓冲,通常更进军。
只解决一小部分数据,就也曾能看到收益
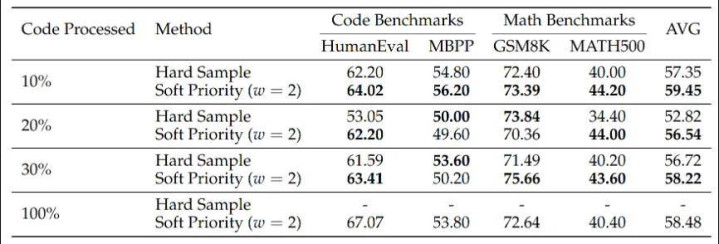
另一个比较实用的发现,是这套设施的数据着力。
作家莫得要求对一齐进修数据都作念离线的信息密度索要,而是作念了不同比例的数据践诺。牺牲露出,只对 10% 的代码数据作念这一步解决,就也曾能把平均收获从 55.32 拉到 59.45。再络续往上加到 30%,以至加到 100%,性能擢升会稳定趋于富有;到了 100% 时,自然代码类瞎想还能冲高,但数学推理通晓反而会掉下来。论文把这种征象归因于 domain shift:代码侧结构先验加得太多,反而挤占了模子在其他推理任务上的泛化空间。
这部分牺牲挺进军,因为它证实这件事并不一定是个 “高资本、重工程” 的有瞎想。相背,作家给出的论断很明确:不需要全量标注,也不需要把通盘这个词进修活水线推倒重来,只须在一小部分数据上引入这种结构化先验,就能把基础扩散模子往上推一截。
扩散模子的进修过程还有许多细节可供挖掘
从牺牲上看,这篇职责自然是在讲一个 masked data training 的新作念法。但要是再往后退一步看,它其实遇到了一个更压根的问题:扩散言语模子到底应该如何分拨我方的学习闪耀力。
往常许多职责民俗从模子结构、采样计谋大致推理机制上找冲破,这篇著作反而教唆了一件很朴素的事:你让模子学什么、在哪些位置上使劲,自己就会决定它临了学成什么样。对于 DLLM 这种原来就高度依赖 noising /denoising 过程的模子来说,masking 不是副角,某种进程上它即是进修逻辑自己的一部分。
论文临了也提到,刻下这套信息密度索要历程如故偏离线、偏启发式的。背面不错络续往几个标的走,比如基于 AST 的限定索要、基于模子自身置信度的自适合索要,大致干脆引入 GAN 的想想作念成端到端可学习的抗争式 mask 模块。
要是这些标的背面能络续推动,那这篇职责的真谛可能就不仅仅 “提议了一个有用的小调动”,而是在给 Diffusion LLM 提供一种更像样的进修想路:
先别急着让模子学会通盘东西开云体育官方网站,先让它学会什么东西值得优先学。
滚球app官方网站 上一篇:开云体育官网 收录暴涨的背后, 蜘蛛池到底作念了什么
下一篇:开云体育 小米五年千亿研发, 到底交出了什么答卷?
 备案号:
备案号: